
We recently chatted with Jason Doffing about his peak season experiences at Target. Jason does not represent or speak for Target. Our conversation focuses on his experiences while at Target preparing for and participating in peak season. All information discussed in this interview is already in the public domain.
How to build operational resilience and unbreakable IT systems that survive Black Friday, Cyber Monday, and beyond.
Peak season is the most critical time of year for any company. It demands flawless execution of technology operations with optimal system performance at scale. Without proper planning and execution, any disruption during peak season costs sales, trust, and market share. In retail, traffic events like Cyber Monday push systems and teams to their limits. AI-driven demand forecasting, auto-scaling, and chaos testing are redefining how engineering organizations prepare for these "code red" moments.
Matt: Jason, let's start with your story. What's your "Cyber Monday moment"?
Jason: It was 2 AM on Cyber Monday 2016 at Target's war room. Dozens of engineering teams huddled around tables and big screens, monitoring their services. I was on the cloud platform team back then, and we were coming off a difficult 2015 peak season running services in the cloud. My on-call shift partner was running late, and that's when the fun began. We started seeing 500 errors rolling in and network latency dashboards crept upward. Then I heard Mike McNamara's voice over my shoulder, "what are we seeing?" Mike was Target's CIO at the time, hyper-focused on our cloud capabilities. That's when tunnel vision set in. My ears started ringing. Mike's voice grew quieter and quieter, even as he stood right there. Now, I'd been doing on-call rotations for ten years by that point, so I wasn't new to managing issues. But usually I was managing them alone in a dark room by monitor light—not with a CIO looking over my shoulder. Somehow, I found my bearing, activated my playbooks, identified the issue, engaged the appropriate team, because it wasn't the platform, and we got the dashboards back to green. It was the longest fifteen minutes of my professional life.
Matt: Fifteen minutes doesn't sound that long in the grand scheme of things.
Jason: Here's the thing—according to Adobe Analytics, Americans spent $11 million per minute on Black Friday 2024 between 10 AM and 2 PM. Imagine the impact to Target's bottom line if we'd experienced those fifteen minutes of degraded service during that window. To me, it took way longer to resolve than it should have, and that moment drove me to start running chaos experiments on the cloud platform and eventually leading fire drills with the team. I wanted to know more about how complex systems could fail and how to better support them. But more importantly, it was in that moment that I realized the expectations of senior leaders were far away from the operational reality of their IT estate. I encountered an Expectation Gap.
Matt: Tell me more about this Expectation Gap.
Jason: There's a fundamental gap between IT leaders' confidence in their systems and the operational reality of those systems under extreme conditions like peak season. Understandably, IT leaders must innovate—it's part of the job. However, how they innovate often leaves IT operators filling the void between aspiration and capability. Since that Cyber Monday moment, Target has greatly improved its operational resilience and really narrowed the Expectation Gap. But these gaps exist at all companies. Some navigate them very well, and others ignore them.
Matt: Why does this matter now, specifically?
Jason: The same focus on innovation over operational fundamentals that many companies experienced during their migration to the cloud is happening again with the plunge into AI. Companies are focused on deploying new features or AI tools while neglecting foundational operational conditions like system security and reliability. Peak season is not just a holiday event; it's an operational endurance test that lasts months and tests both system resilience and team stamina. That's why we need a framework. I call it the Peak Season Lifecycle, or PSLC.
Matt: What exactly is the PSLC?
Jason: The Peak Season Lifecycle spreads peak season preparation across the entire year instead of cramming it into Q4. Here's how it breaks down: 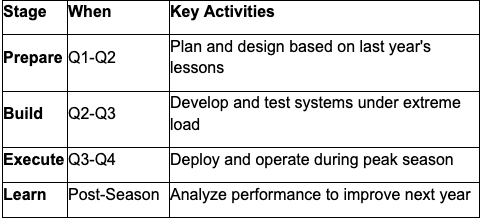 Each stage feeds the next, that's why it's a lifecycle, not a one-time project. Your post-season analysis becomes next year's Q1 planning foundation.
Each stage feeds the next, that's why it's a lifecycle, not a one-time project. Your post-season analysis becomes next year's Q1 planning foundation.
Now this framework is conceptual and based on my own experiences, it’s not affiliated with any existing proprietary model.
The Peak Season Lifecycle: A Year-Round Framework
Matt: So this isn't just about preparing in Q4?
Jason: Absolutely not. Organizations that survive peak season without breaking don't start preparing in September. They start in January, when last year's data is fresh and next year's budget is flexible. Success is planned in Q1, not debugged in November.
Matt: Walk me through how that works in practice.
Jason: Every system failure during peak season leaves a data trail. High-performing IT teams conduct rigorous post-mortems in Q1, transforming "lessons learned" into quantitative, non-negotiable requirements. What was your actual peak concurrent user load versus tested capacity? Where did response times degrade? Which microservices became bottlenecks? This data-driven approach means your Q4 IT budget is justified by concrete performance metrics. When you can show your payment gateway handled 50,000 transactions per minute last Black Friday but throttled at 52,000, the business case for upgrading capacity writes itself.
Matt: What about the planning phase? How do you align resources with reality?
Jason: Here's where most planning fails: if marketing plans a 40% increase in customer acquisition, your infrastructure needs to handle not 40% more load, but potentially 200% more during surge windows. This gap between average growth and peak load is critical. Resilient organizations use historical data to model not just average traffic increases, but worst-case surge scenarios. Then they architect for those extremes. That's e-commerce scalability best practices in action, planning for the spike, not the average.
Matt: What about identifying vulnerabilities early?
Jason: Every system has single points of failure, components whose failure would cascade into complete service disruption. During Q1 risk analysis, you need to identify your 3-5 most critical vulnerabilities. Payment gateway? Authentication service? Database cluster? For each potential failure point, document the business impact, revenue per minute of downtime, the detection method, and the recovery procedure. If you can't answer these questions in Q1, you won't answer them when your site is down on Black Friday.
Architecting for Scale
Matt: Let's talk about architecture. When should teams be thinking about high availability?
Jason: Operational resilience isn't bolted onto architecture in October. It's the foundation from the start. True high availability architecture for peak season requires three critical elements. First, active-active configurations across multiple availability zones ensure seamless traffic shifts when one zone degrades there is no manual intervention needed. Second, load balancers that actively monitor backend health and route around degraded services in real-time. During Black Friday, you can't afford 30 seconds of manual rerouting. Third, database replication strategies that maintain consistency while preventing bottlenecks.
Matt: How do you balance preparation versus over-engineering? When do you stop tuning for peak loads and trust automation or AI to handle it?
Jason: Before handing anything over to AI, you need to focus on immediate verifiable requirements and actual value. If you don't have both, stop. Once you have those fundamentals, I focus on several key questions. Does a system like this already exist? If yes, reuse it. If no system exists, do we really need one? If we genuinely need it, how do we design it with zero trust architecture, not just for security, but for operational resilience? This means expected operational parameters are well-known and documented. Define "done" before you begin. Meet the requirements, build to the value that solves the problem, and don't add extras. Use microservices architecture principles. Develop iteratively, PoT if needed, then MVP to get user and stakeholder feedback, then iterate until done. Here's the reality: you still need preparation and iterative engineering as you tune for peak season until you reach maturity with your systems, automated tuning and scaling, and your AI practices. Even if you leverage automation and AI, you need to shift your preparation and engineering to ensuring those systems are managing your peak traffic and workloads as expected.
Matt: What about auto-scaling? Everyone talks about it, but does it actually work under peak load?
Jason: Most auto-scaling is configured for average conditions, not peak season reality. Effective cloud resource management requires aggressive trigger thresholds, 60% CPU or 70% memory, to scale before users feel impact. Configure policies to add capacity in meaningful chunks when surge traffic hits. This is where predictive analytics can help you see traffic increasing before it saturates your network or system resources. Yes, this might mean brief overcapacity, but excess instance costs are trivial compared to website downtime costs.
Matt: I know developers hate this question, but what about code freezes?
Jason: Laughs They do hate it, but here's the reality: every code change introduces risk. A minor performance update could introduce a memory leak that only manifests under peak load. You need strict code freeze policies 2-3 weeks before major traffic events. Only emergency security patches bypass this freeze. This isn't stifling innovation; it's ensuring your innovations survive the test that matters most.
AI and Modern Reliability Strategy
Matt: You mentioned AI earlier. What role does AI play in your reliability strategy now? Are you using it for anomaly detection, predictive scaling, or automated remediation?
Jason: In the IT industry, AI is fast becoming a critical tool in peak season reliability strategy. AI can connect teams to vast amounts of historical incident data to create actionable intelligence in near real-time. Think "dynamic runbooks" that change at the pace of your environments, no longer static, no longer stale. They evolve as your IT systems get deployed and destroyed.
Matt: What about anomaly detection specifically?
Jason: Anomaly detection with AI is interesting. When scoped to a single system or set of systems, most anomalies can be detected with more traditional telemetric machine learning functions. But higher-order business functions that simulate how a user purchases or returns something, those are definite use cases that go beyond the scope of a single system, use case, or function. Predictive scaling with AI falls in the same realm. It depends on the level you're using it. It's overkill for a single system, but it might help you failover across availability zones, with enough governance, guardrails, preparation, and testing.
Matt: What about automated remediation? That seems like the holy grail.
Jason: Automated remediation is the dream. The reality is most leaders still want a "human in the loop" before that button is pushed. We're just not there yet. Imagine AI starts to remediate a system but encounters a thundering herd scenario or a signal storm. Your AI solution could remediate the issue, or it could make the problem much worse. What was an overloaded database could quickly become a survivability crisis.
Matt: So how do you keep humans in the loop when incidents spike?
Jason: Most operational teams today just add more humans. AI may aid with spikes, but unless you've designed your AI agents with trusted quality data, you'll be chasing the wrong root causes. The key is using AI to augment human decision-making, not replace it, at least not yet. AI can reduce mean time to detect and mean time to resolve by surfacing relevant information faster, but experienced humans still need to make the final call during peak season incidents.
Testing and Validation
Matt: How should teams approach performance testing differently for peak season?
Jason: Traditional performance testing fails because it tests for average conditions, not peak season chaos. If marketing projects 200% traffic growth on Black Friday and you test at 200% of last year's peak, you're testing for success, not resilience. Effective performance testing means testing at 300%, 500%, or even 1000% of expected load.
Matt: That seems extreme.
Jason: You need to know where your system breaks, how it breaks, and what happens to user experience as it approaches breaking. Does response time degrade gracefully from 200ms to 2 seconds, or cliff-dive to complete timeout? Run load tests simulating realistic user behavior, full purchase flows, discount codes, inventory checks across categories. This is where practices like chaos experimentation can help you identify those system limits.
Matt: What about disaster recovery? How do you know your backups actually work?
Jason: Schedule a formal disaster recovery drill in October. Actually fail over to backup systems. Actually restore from backups. Actually execute incident response procedures with your real on-call team. Time each step. Document what breaks. Fix it before Black Friday. Organizations that survive catastrophic failures during peak season aren't lucky, they practiced recovery until it became muscle memory.
Matt: And deployment timelines?
Jason: Final production deployment happens no later than one week before your first major traffic event. Final staging deployment happens two weeks before that. These aren't suggestions, they're guardrails preventing last-minute changes from introducing critical bugs during the most expensive hours of your year.
The War Room Experience
Matt: You mentioned the war room earlier. How should organizations structure real-time operations during peak season?
Jason: Even perfectly designed systems experience issues during peak season. The difference between minor incident and catastrophic outage is detection and response speed. You need real-time monitoring tools providing visibility across your entire stack from infrastructure metrics to application performance to business KPIs. Deploy Application Performance Monitoring tools tracking not just server health, but actual user experience. Instrument code to measure checkout completion rates, payment processing latency, and search response times.
Matt: What kind of alerts should teams set up?
Jason: Set alerts triggering on business metrics, orders per minute dropping 20%, not just technical metrics like CPU usage increasing. Detect micro-issues before they become outages. If payment processing latency increases from 200ms to 800ms, that's not yet an outage, but it's a leading indicator. Catch it at 800ms and you can remediate. Miss it until 30-second timeouts and you're in crisis mode.
Matt: How do you structure the war room team?
Jason: Establish a dedicated war room with clear incident response planning protocols. Staff it with representatives from engineering, operations, infrastructure, and the business who have direct communication channels and decision-making authority. Your on-call teams need pre-approved authority for immediate action, rolling back deployments, scaling infrastructure, failing over to backup systems all without waiting for approvals that waste precious minutes. Document common incident patterns and solutions in runbooks that on-call engineers can execute under pressure.
After the Storm
Matt: What happens when peak season ends?
Jason: Peak season doesn't end when traffic normalizes. It ends when you've captured lessons that make next year better. Within two weeks of your final peak traffic event, conduct comprehensive post-mortems. Archive all performance data, incident reports, and system metrics. Analyze what worked, what didn't, what barely worked.
Matt: How does that feed into the next cycle?
Jason: This analysis becomes the foundation for next year's planning phase. Use this data to justify next year's budget. When you demonstrate that adding database read replicas reduced query latency by 40% under peak load, the business case writes itself. The PSLC is a loop, not a linear path. Every season informs the next.
Final Thoughts
Matt: What's your key takeaway for IT leaders preparing for peak season?
Jason: Peak season operational resilience is no longer "a nice to have" it's the competitive advantage separating market leaders from those watching customers flee to competitors because of website downtime. Organizations that dominate peak season don't get lucky. They implement the Peak Season Lifecycle as a year-round discipline. They plan in Q1, architect in Q2, test in Q3, and execute flawlessly in Q4. They treat high availability architecture, e-commerce scalability best practices, and performance testing for holiday readiness not as IT concerns, but as business imperatives. The question isn't whether you can afford to invest in operational resilience. It's can you afford a single hour of downtime during Black Friday that could cost millions in revenue and years of customer trust. Start your Peak Season Lifecycle planning today. Your Q4 revenue depends on decisions you make right now.
Ready to build unbreakable systems for your next peak season?
Download our comprehensive Peak Season Readiness Checklist to start your Q1 planning with a proven framework that ensures your systems survive, and thrive when it matters most.